How Data Teams Can Supercharge AI with Better SQL Queries
See why thousands of data teams are revolutionizing AI with smarter SQL queries!
2 min read
https://haystack.deepset.ai/blog/business-intelligence-sql-queries-llm
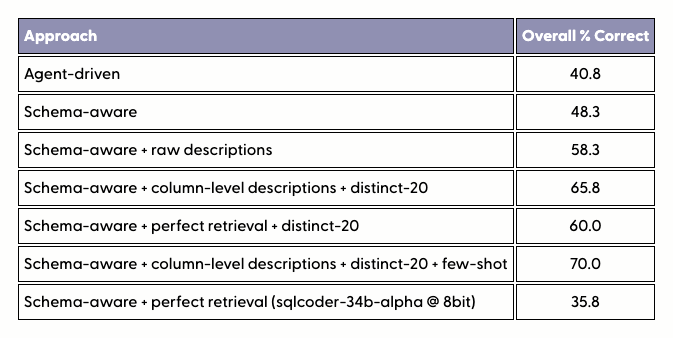
Schema aware context:
- Results in very long prompt
- Costly to run without caching or LLM memory
- Gives much better accuracy
- Needle in a haystack problem
Agent:
- Can discover schema and sample rows without explicitly brute forced into the prompt. Solves above problem
- Will guarantee valid sql because agent can run it before giving it to user
- After bunch of discovery, agent may end up in super long prompts with data, schemas etc.
- Agents are more black-box to users and so harder to debug and explain
For the data teams to extract more value out of AI, they should be focusing on:
- HQ Data Model: Model data properly to remove ambiguity and redundancy in the way the data is structured
- Detailed schema: Create detailed schema for the data model with table and column level description
- Sample traits of the data: Create distinct 20 values of each column for the context of what are the values of a col.
- Generate some example: LLMs will perform better with few shots. This implies data team should look back and create pairs of objective in natural language and resulting accurate SQL.
- Fewer Tables: Because table retrieval is not accurate it makes your tweak your data model. The better data model for AI would have fewer wider tables so it can easily match the query to the right subset of tables.
I don't think its possible for individuals to hand curate all this information when querying LLMs. So the existing (or new) tools will have to assist them.
Some tools that come to mind:
- Data Quality and Catalog Tools
- Semantic Layer
- Data Lineage Tools
- Headless browsers or analysis queries
A New startup should not be building all these things from ground up. A lot of these already exist and have been innovated on in the past couple of years.