How To Create An AI Budget Assistant Using LLMs In Just 60 Days
Here's why everyone is talking about using LLMs for personal finance—start your AI budgeting journey today!
Imagine creating an AI budget assistant with gpt-3.5!
Here's my journey of building an LLM app to classify and analyze my budget. It's more about categorization than analysis—after all, analysis of our spending isn't that hard; ChatGPT can do it with one big CSV.
As a data and machine learning engineer, automation has always been my north star. Over the past few years, I've automated data flows, model training, and deployment, aiming for efficiency and making them less error-prone. Recently, I embarked on a 60-day plan to master LLMs.
This is my experience tackling a seemingly simple NLP task using LLM tooling and best practices.
Some Background: Manual Categorization Woes
For personal budgeting, I use YNAB 1. While it's a great tool, manually categorizing transactions can be tedious and error-prone. This inefficiency often leads to procrastination, and let's face it, no one wants to spend their time manually clicking through transactions.
My motivation? Curiosity and the itch to automate what I can.
I wanted to explore how basic language models fare on classification tasks for transaction categorization. Intuitively, it seems like a straightforward task for large LMs, so why not dive in and find out?
Here is the example Task. This is simple for us humans.
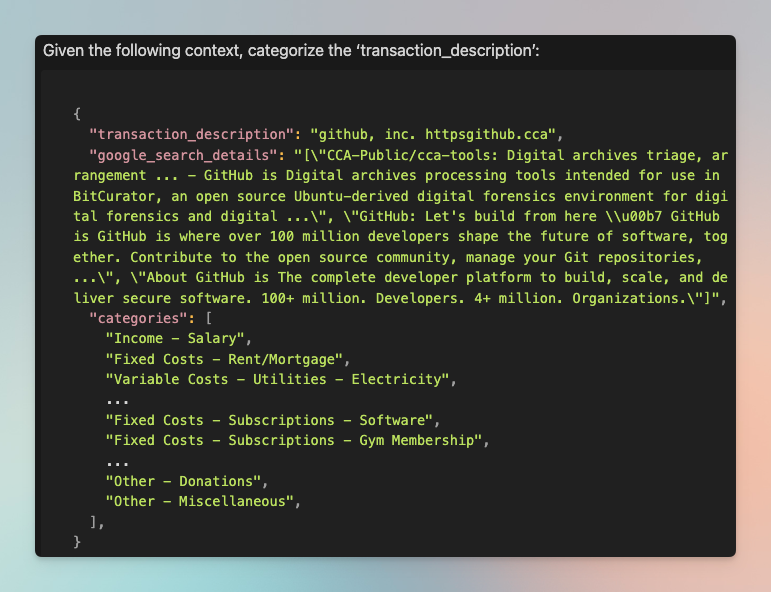
- transaction_description: The raw description of the transaction as it appears in the bank statement. This example includes "github, inc. httpsgithub.cca," which indicates a transaction related to GitHub.
- google_search_details: I included search results from Google to enhance the context. This additional information provides the model with a richer understanding of what the transaction might be related to. For instance, the details describe GitHub as a platform for developers, which helps accurately categorize the transaction. I used serper.dev to get google search results via API.
- categories: A predefined list of potential categories the transaction could fall into. These categories cover a range of common expense types, from "Income - Salary" to "Fixed Costs – Subscriptions – Software" and "Other – Miscellaneous."
Guiding Principles
1. Avoid Accidental Complexity
Minimize unnecessary complexity. Use a limited number of libraries to maintain control and understand the model's behavior. Hamel describes it best in this post.
 Fuck You, Show Me The Prompt 2
Fuck You, Show Me The Prompt 2
2. Iterative Experimentation
Adopt an iterative approach. Start with basic prompts and refine them based on responses. Continuous experimentation and optimization are key. LLMs are still black boxes, and given input, it is hard to understand why they behave the way they do.
3. Build Evals!
Evals are key to working with non-deterministic models in a larger software system. It's very hard to improve systematically without having proper evaluations set up for your task.
Let's us look at some results first
gpt-3.5-turbo was very slightly better than gpt-4o 😲
The graph below shows the accuracy numbers of my experiments. Accurate result is when the category predicted matches the category of the human evaluated gold dataset. Look at how close gpt-3.5 and mixtral are to gpt-4o!
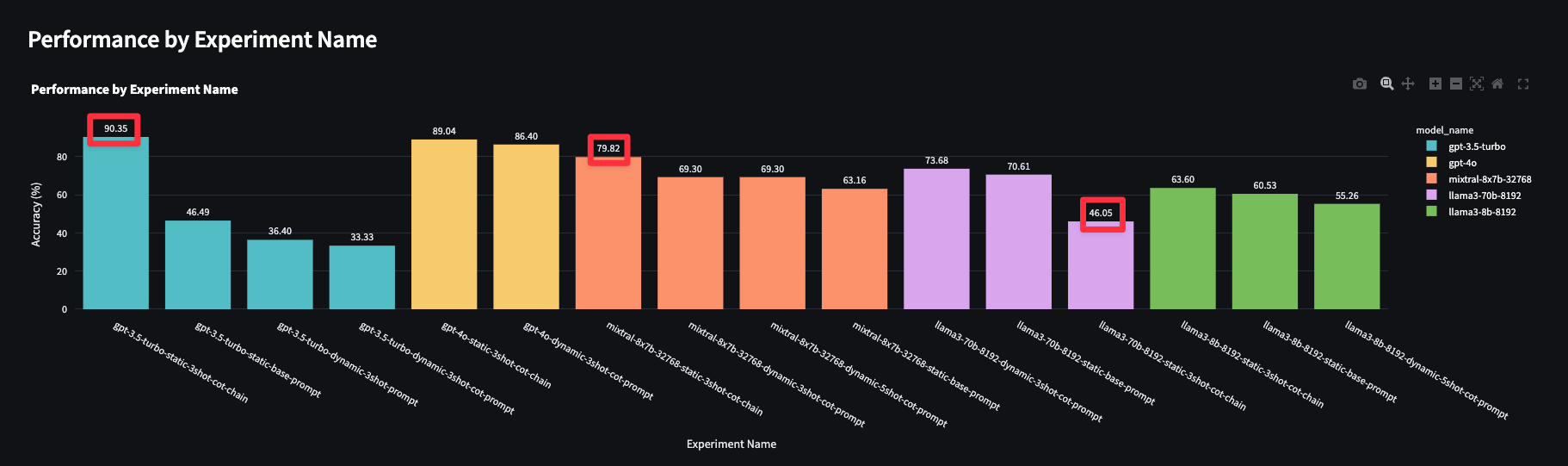 2 step chain performed the best on categorizing transactions correctly. The details and the prompts are discussed later in the implementation details.
2 step chain performed the best on categorizing transactions correctly. The details and the prompts are discussed later in the implementation details.
One of the reasons why gpts perform better is OpenAI is really good with function calling and 2nd step here is all about function calling with the json schema. Groq based Llama-70b struggled a lot with that.
The more detailed the context, the better the result.
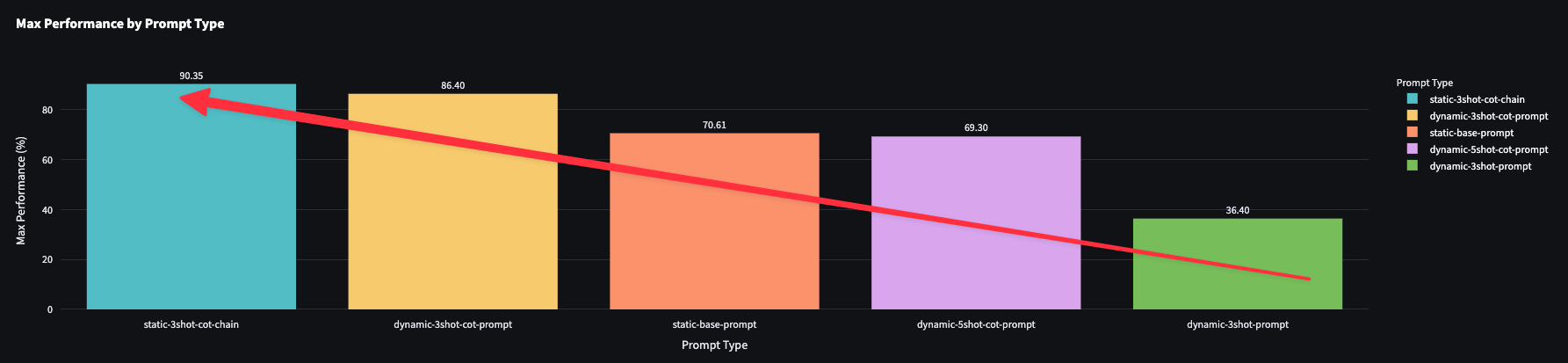 The two step chain had the most amount of tokens and the best performance. Extrapolating this result, if I can put more examples in the prompt and I don't care about latency and cost but prefer accuracy then I will get better results.
The two step chain had the most amount of tokens and the best performance. Extrapolating this result, if I can put more examples in the prompt and I don't care about latency and cost but prefer accuracy then I will get better results.
Don't assume a bigger model is always slower!
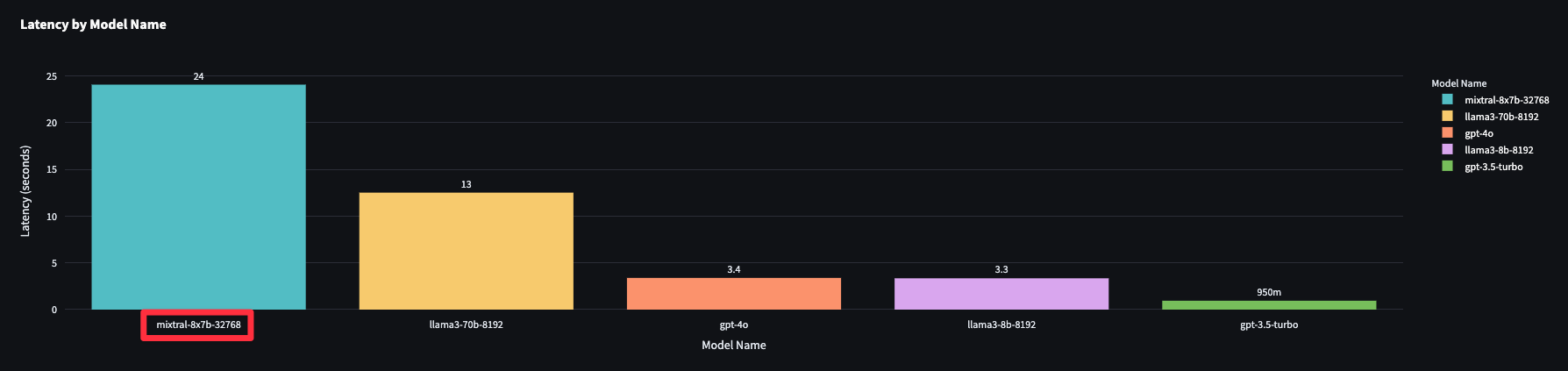 Mixtral 8x7B which is the smallest model of all was the slowest of all too. I used Groq for inference and we are looking at avg latency across all experiments.
Mixtral 8x7B which is the smallest model of all was the slowest of all too. I used Groq for inference and we are looking at avg latency across all experiments.
Implementation details:
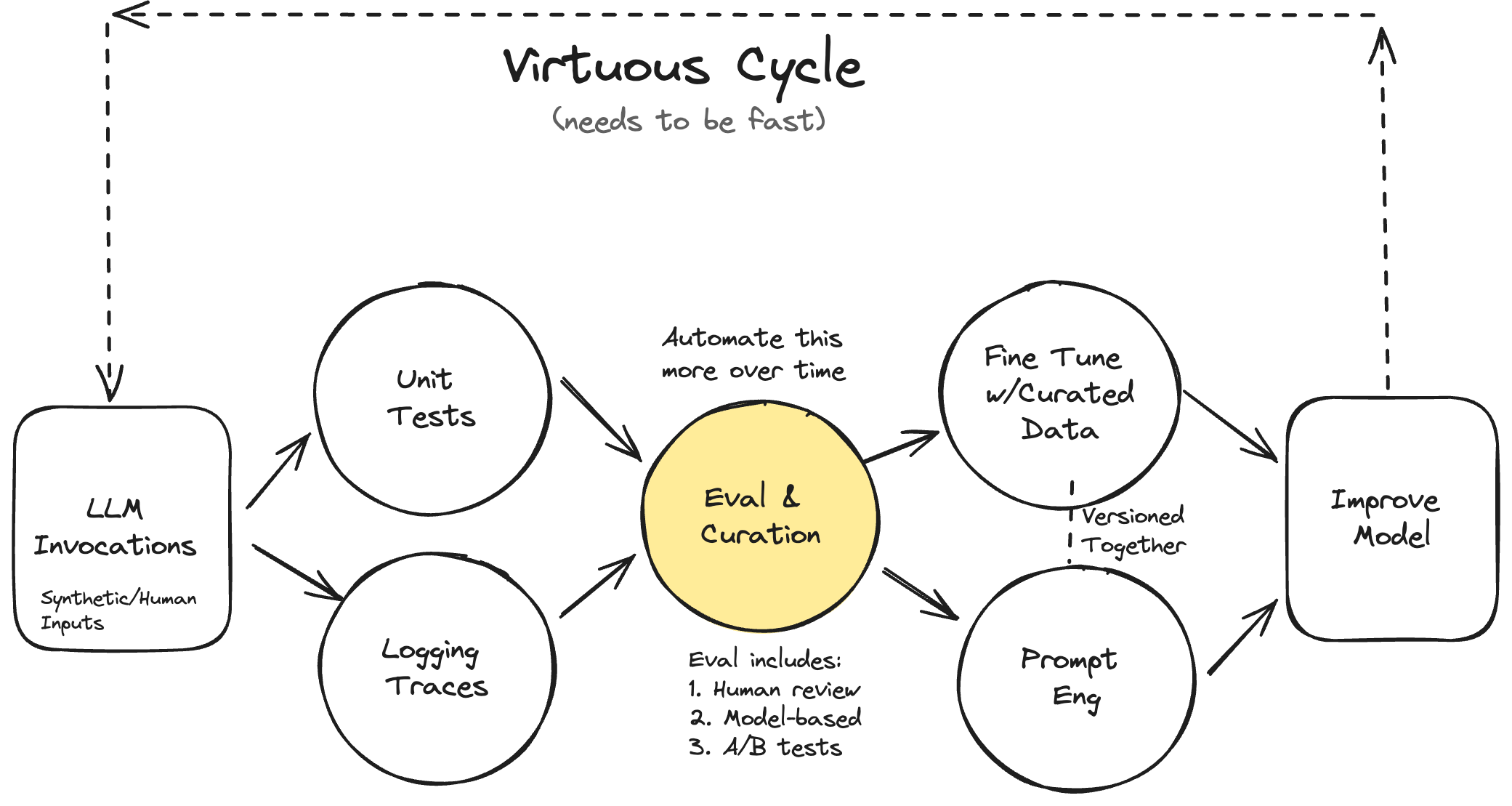 Your AI Product Needs Evals 3
Your AI Product Needs Evals 3
This was my process to do the iterative virtuous cycle:
- Get clean data
- Simple script with basic prompt(s) to the task
- Manually annotate transactions for a few mins
- Integrate with LangSmith to log traces
- Run experiment on unique inputs
- Evaluate manually and look at the data in LangSmith
- Improve prompt, code, and go back to the beginning
1. Get clean data: Laying the Foundation
The first step was collecting transaction data from various financial accounts.
I downloaded all the transactions from my bank accounts. Then, I enriched this data using the Google Search API to add more context. Standardizing the schema, ensuring correct data types, and preparing the dataset for model training was a time-consuming but crucial step. One important piece of advice that was emphasized during the course by Hamel is, "Look at your data." This advice often goes unspoken in blog posts about fancy RAG applications, yet it remains a high-value task for building successful applications using LLMs or traditional ML alike.
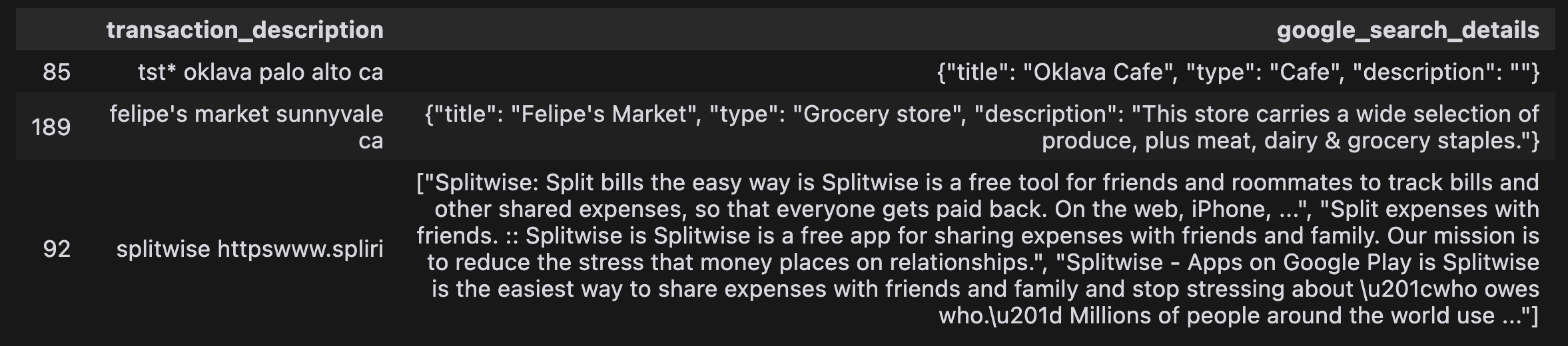
For the last three months, I had around 229 unique transactions.
So please “Look at your data”!
Mine looks like this:
2. Initial Experimentation: Starting Simple
Starting simple is key.
I used the Instructor Python library to implement a basic classification with LLaMA3 8B and OpenAI. I started by simply copying one of the examples from the cookbook and diving in. The guiding principle to focus on here for me was accidental complexity. I wanted to stay close to the LLM API calls but still get reliable outputs in a predefined schema.
A great starting point is with Instructor and OpenAI 4:
from typing import List
import enum
from pydantic import BaseModel
from openai import OpenAI
import instructor
# Step 1: Define Enum with categories
class BudgetCategory(str, enum.Enum):
INCOME = "Income"
RENT = "Rent"
GROCERIES = "Groceries"
ENTERTAINMENT = "Entertainment"
# Step 2: Define the multi-class prediction model
class BudgetItem(BaseModel):
"""
A class representing a budget item.
"""
description: str
budget_category: BudgetCategory
# Step 3: Setup a prompt
prompt_template = """
You are a personal budget app which classifies transactions. Use the description of the transaction to define its category.
Description: {transaction_description}
Category:
"""
# Step 4: Setup call to OpenAI with instructor
# Apply the patch to the OpenAI client
# enables response_model keyword
client = instructor.from_openai(OpenAI(api_key=os.getenv("OPENAI_API_KEY")))
def classify_transaction(description: str) -> BudgetItem:
"""Classify the transaction description into a budget category."""
prompt = prompt_template.format(transaction_description=description)
return client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "user",
"content": prompt,
},
],
response_model=BudgetItem,
)
# Step 5: Do a call with example transaction
example_description = "Dinner at a restaurant"
classified_item = classify_transaction(example_description)
print(classified_item)3,4,6. Monitoring and Evaluation: Keeping an Eye on Performance
To monitor and evaluate the model, I integrated LangSmith to trace calls to the LLM, tag inputs and outputs, and annotate results, creating an evaluation dataset.
Building a dataset through manual verification and annotating model outputs was an eye-opener—it was surprising how often the models couldn’t get it right out of the box.
Why did I choose LangSmith? They offered course credits 😜 and Harrison was available for office hours. Integration was easy with LangChain, and it reduced my codebase significantly.
This is all you need to setup detailed tracing:
LANGCHAIN_TRACING_V2=true
LANGCHAIN_API_KEY='my_langchain_api_key'I logged over ~7700 traces to conclude the experiment. There are a lot of great metrics out of the box which helped me investigate latency, cost, token usage, error rate for apis and review at the data.
5,7. Iterative Prompting and Model Comparison: Refining the Approach
I experimented with different prompts to improve classification performance. It was crucial to compare various models. I tested Mixtral 8x7b, LLaMA3 70b, LLaMA3 8b, gpt-3.5-turbo, and gpt-4o.
Basic One-Shot prompt
Categorize the transaction based on the description and Google search of the description with function calling.
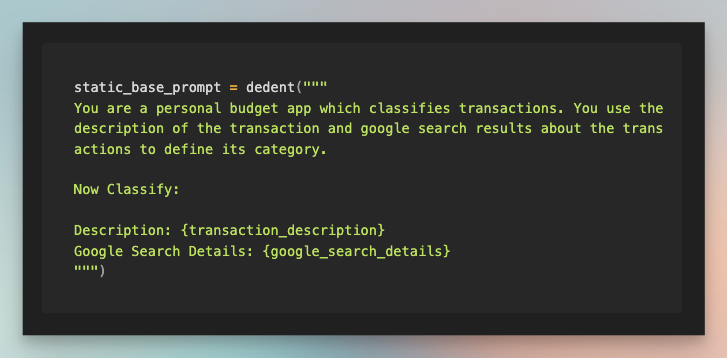
Dynamic few-shot prompt
I tried both 3 and 5 examples to categorize the transaction based on the description and Google search of the description with function calling.
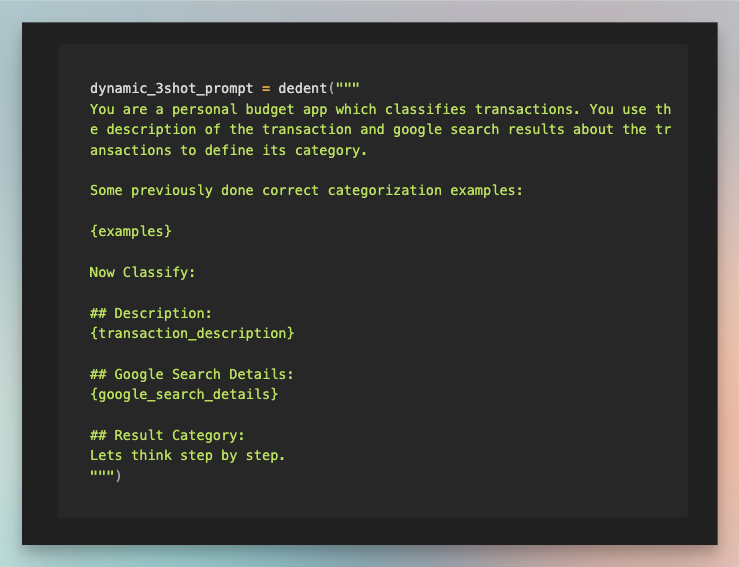
Static Few-shot with CoT
I hand crafted chain of thought with examples. How would I look at transaction description and google search results and categorize a transaction.
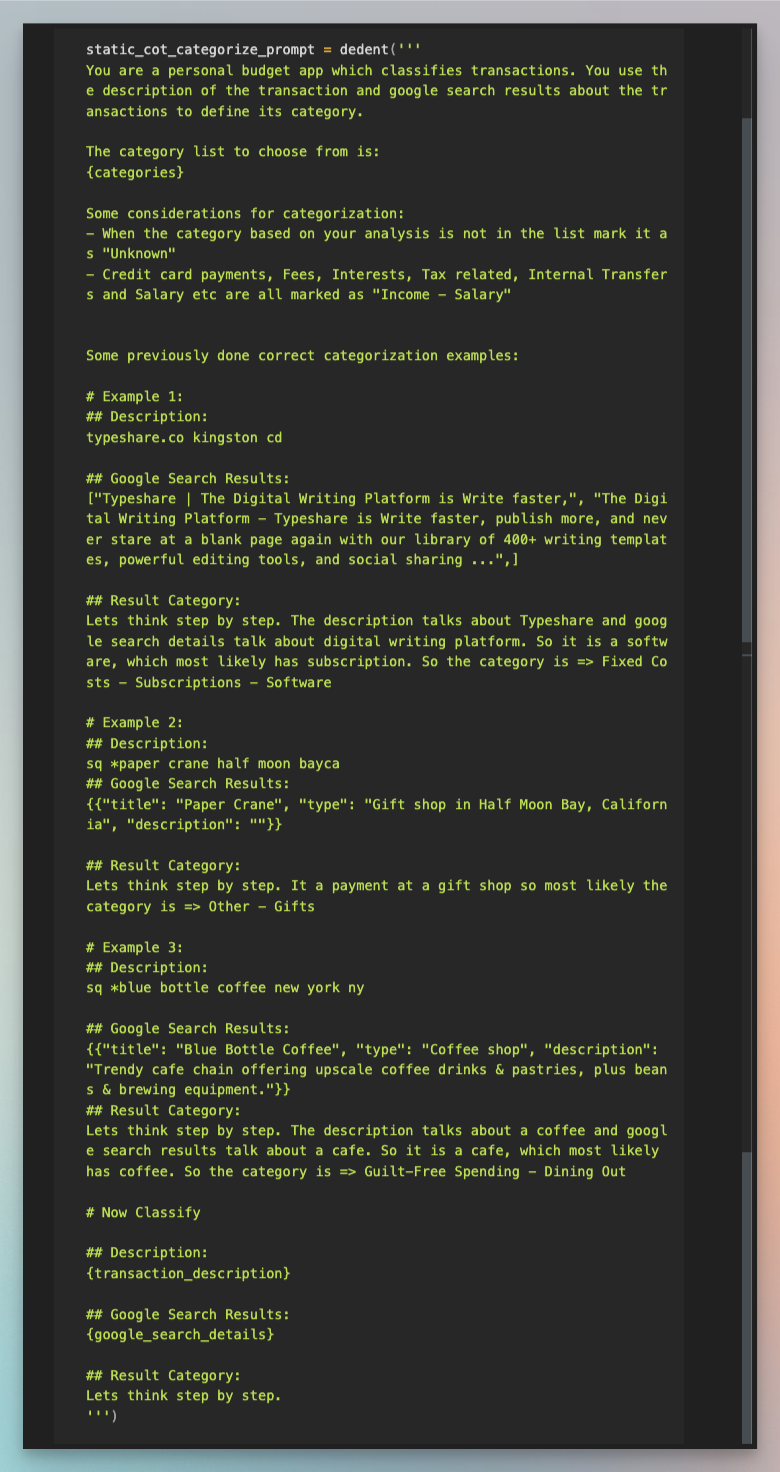
Two-step Chain
I wanted to separate Chain of Thought from function calling so I broke it into two steps. One feeding the second. These are the two steps.
- Static Few-shot (3 examples) with CoT (Same as above)
- Parse category with function calling
I found prompt engineering can be quite challenging for various reasons:
- Ambiguity and Context: Slight changes in wording can lead to vastly different responses from the model. For example, asking “Describe a tree” might yield a botanical explanation, while “Describe a tree in a fairy tale” prompts a whimsical, magical description.
- Iterative Process: Effective prompt engineering often involves trial and error. You start with a basic prompt and refine it based on the responses you get. This can be time-consuming and requires careful attention to detail.
- Lack of Standard Guidelines: Unlike traditional programming, prompt engineering is relatively new and lacks standardized guidelines. Practitioners often rely on intuition and experimentation, leading to a steep learning curve.
- Model-Specific Behavior: Different language models may respond differently to the same prompt. We don’t know why (as of yet); if something that works well for one model will be effective for another, necessitating prompt adjustments.
Prompt engineering is an art that combines creativity, clear communication skills, and a deep understanding of language model behavior.
Lessons from the Journey:
- Start Simple: Emphasize the value of beginning with a straightforward problem to master the fundamentals.
- Variability in LLMs: Working with LLMs means embracing non-deterministic behaviour; same inputs can yield different results. Precision is important, but I found its easier to be flexible with requirements where possible.
- Balancing Costs: Constantly watch out for the costs. Currently, cost can be prohibitive to running different experiments at scale.
- Tailor Benchmarks to Your Needs: General benchmarks don't always apply to your tasks. Less "intelligent" models can outperform sophisticated ones, depending on your needs. For example, Mixtral, an affordable model, performed almost as well as GPT-4 in my experiments. Run evals yourself.
Personal Insights: Navigating the Challenges of LLMs
Working with LLMs has been a mix of excitement and overwhelm. The sheer number of tools and technologies can be daunting.
I actively avoided:
- Tool Overload: With so many platforms and frameworks, it’s easy to feel lost. Prioritizing the basics and taking it one step at a time helped me stay focused.
- FOMO created by social media: There are so many flashy demos of AI doing magic. It is very tempting to look at the code and learn from it. Reminding myself that solid ML fundamentals are key helped me keep on track to finish this project.
I actively focused on:
- Controlled Experiments: Helped me understand model behavior.
- Versioning: Kept track of models, data, and prompts to ensure reliability.
- Data Quality: Good data is crucial for LLM success.
- Prompt Engineering: Crafting effective prompts is like feature engineering.
- Relevant Metrics: Used the right metrics to assess models.
- Continuous Testing: Ran evaluations during CI/CD to catch issues early.
Hamel’s course 5 helped a lot in having a guided path in navigating the LLM landscape.
If you read till, I appreciate you for spending time with me out of your busy day :). What are your current problems in using LLMs? I would love to hear from you. Please reach out!
Footnotes
-
YNAB (You Need a Budget) is a personal budgeting software that helps users gain control over their finances by promoting proactive planning and mindful spending. It employs a unique methodology focused on assigning every dollar a job, tracking expenses, and adjusting budgets in real-time to achieve financial goals. ↩
-
Insightful essay on how libraries inject/morph your prompts before sending it to LLMS https://hamel.dev/blog/posts/prompt/ ↩
-
Hamel talks about how to tactically approach Evals. https://hamel.dev/blog/posts/evals/ ↩
-
A lot of great examples at Instructor Docs to get started with structured outputs from LLMs ↩
-
Amazing course setup by Hamel and Dan. LLM-conf + finetuning workshops at https://maven.com/parlance-labs/fine-tuning ↩