How we won Code Interpreter 2.0 with ProoferX
The Agentic AI that ensures code reliability and completeness in Docs!
Look, we all know the deal - good tech products need solid docs and examples. Developer experience and trust are essential for these products to grow. Out-of-date code examples in public technical documentation can really hurt the product builders.
Here are some examples we stumbled upon:
- OpenAI structured output introduction is broken. They are a pointer to the data files used to run the summarization code.
- Vite installation docs don’t work. This is a wrong first impression for a junior developer. They have a GitHub issue open for it here.
- E2B documentation guide for devs to use API key is broken for Python. It was a small typo, so not the biggest deal, but it theoretically proves our point.
It is un-imagineable to expect a team to manually check that their guides work for all the versions of the libraries used in the examples for all the OSes for different versions of compilers the user is using. The only way to achieve this is through automation.
In this hackathon, our goal was to attempt this while learning E2B code interpreter for the first time.
So we put our heads together to solve this.
The mission?
With just a click of a button evaluate if the code in a technical guide or documentation is complete and functioning.
Here is a run through of ProoferX, AI automation to check your technical docs and guides:

At a high-level we need to do this:
Step 1: Extract that code! Read the blog post and create full end to end working code snippets using the blog post and docs.
Step 2: Define success. What's the desired outcome for the reader?
Step 3: Sandbox time! Run that code in a fresh environment and validate it works as expected. This replicates what happens with your readers.
Our Journey
Before the hackathon:
Based on experience from previous hackathons, I did my homework.
We read about the guides sponsors were providing. What credits are available? ;)
Finding like-minded people in the 30 mins at the start of the hackathon is difficult. So, before the day, I met with Selvam and got my team together. We aligned our interests and skill sets beforehand.
We love starter kits. So we came prepared with a starter kit, links to cookbooks, and relevant documentation indexed by Cursor. Cursor is my IDE of choice.
During hackathon:
We connected with partners/mentors to learn who to ask for help if we get stuck. Quick brainstorms and tricks to use undocumented features of newly released products can often be a big unlock.
We chalked a data flow diagram similar to this one.
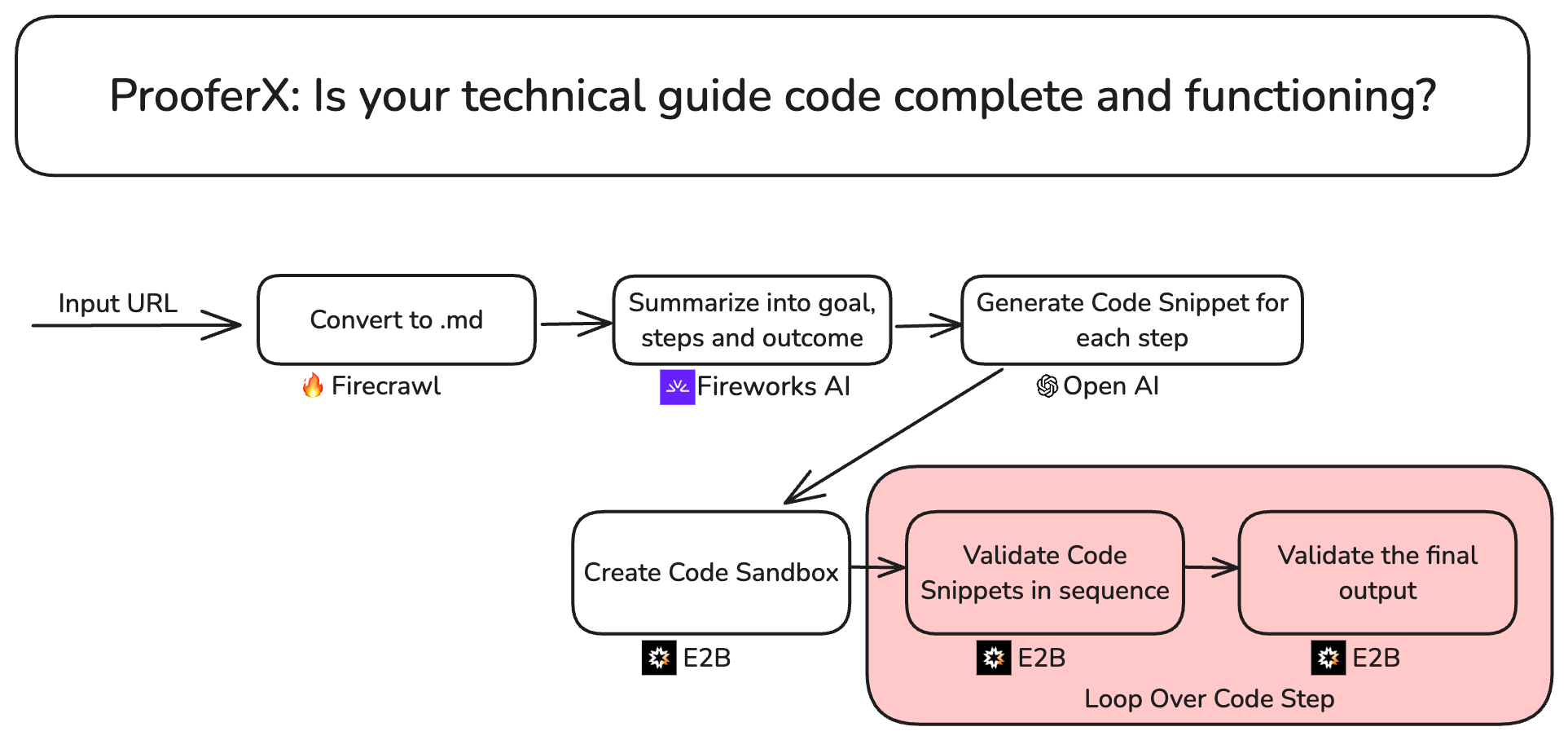
Our strategy was to sync-up every 45 mins and merge our code together.
We started with a simple chain of prompts. This approach helped us understand the types of problems that LLMs excel and suck at solving.
An LLM-friendly version of a guide was easy to get. Firecrawl worked great in converting most URLs into markdowns. Sometimes, people use dynamic code instead of static for their docs; this can cause problems. We decided to tackle that later.
Then, we iterated on the data structure to hold all the important data we wanted to extract. We relied on Pydantic for that. Pydantic plays well with Langchain structured output methods.
The hardest part was to generate a dataset of input articles and correct code snippets for few shot prompting. We focused on getting 2 to 3 articles to work for the hackathon and later spent more time improving this component. Logging our experiments in Langsmith helped us progress towards better prompts.
It is still a work in progress. Getting the LLM generated code to execute is hard! There are lot of places where things can go wrong. For example, getting the incorrect versions of libraries, not having the right ENV variables, not having the right sequence of code to execute etc.
Here is what crewAI logs look like when processing a doc.
Reflections:
- Agentic > CoT: We built a crewAI application that iteratively extracts all the code completely and correctly. This has much better recall than a simple chain of thought. Based on vibes only.
- E2B sandboxes made it easy: We got super fast spin-up time and an easy-to-learn SDK. Shout out to them for an incredible product!
- Fireworks AI: We used Llama 3.2 models to get excellent outputs for extracting essential information like goals, summaries, and steps from the markdown article. It was cheap so that we can iterate on the prompts freely.
- Dependency hell in Python hurts! If you are a Python developer, you know the pain. This also affected the ProoferX. We are working on improving its reliability.
- Multiple illustrations are intricate to get right: Most blog posts have multiple examples. Brute force merging of all code into 1 file won’t cut it.
- Fun one: Stay away from junk food if you want to boost your mental performance. Taking care of your physical and mental state is an underappreciated alpha for winning hackathons.
At the end of the day, we proved feasibility of a semi-automated technical docs checker and elevate the experience of your developers and users. No more broken docs!
So what's next?
We are working hard to launch this as a reliable product everyone can use.
There are a lot of high-value use cases that can be unlocked with running code from guides in an isolated sandbox. Some ideas we have are:
- DevTool companies will proactively fix user facing guides.
- Product teams can create ready-to-run apps for their blog posts.
- Sales could spin up custom sandboxes with API keys on tap.
Stay tuned for updates on this.